Mastering Sklearn Decision Tree: Boost Your Data Science Skills
In the realm of data science, choosing the right tool can mean the difference between mediocre and outstanding results. Sklearn’s Decision Tree algorithm offers a powerful and flexible approach to tackling a wide range of predictive modeling tasks. With its ease of use and robust performance, it has become a go-to method for many practitioners. In this article, we will explore the intricacies of the Sklearn Decision Tree, providing actionable insights and real-world examples to elevate your data science proficiency.
Key Insights
- Primary insight with practical relevance: Understanding the hyperparameters and tuning them can significantly enhance the model's performance.
- Technical consideration with clear application: Handling imbalanced datasets and feature selection can be crucial for decision tree optimization.
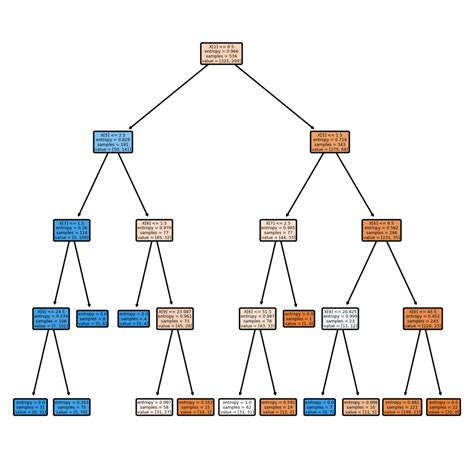
- Actionable recommendation: Always visualize the decision tree to gain insights into feature importance and model decisions.
Understanding Hyperparameters
When dealing with decision trees in Sklearn, hyperparameters play a critical role in dictating the model’s structure and performance. The main hyperparameters to consider aremax_depth, min_samples_split, and min_samples_leaf. For instance, max_depth determines the maximum number of levels that a tree can have. A deeper tree might overfit on training data but generalize better on unseen data. Conversely, limiting the max_depth can prevent overfitting but may underfit. Tuning these parameters requires balancing model complexity with the risk of overfitting or underfitting.
Feature Selection and Imbalanced Datasets
Feature selection is another pivotal aspect when working with decision trees. Using methods like recursive feature elimination (RFE) can help identify and retain the most informative features, which can lead to more efficient and accurate models. When dealing with imbalanced datasets, techniques such as undersampling the majority class or oversampling the minority class can help. Sklearn offers theRandomForestClassifier with an oob_score (out-of-bag score) that uses bootstrapped samples to mitigate the effects of imbalance, providing a robust alternative to standard decision trees.
How do I prevent overfitting in a Decision Tree?
To prevent overfitting, you should consider limiting the tree's depth using `max_depth`, setting a minimum number of samples required to split an internal node (`min_samples_split`), and setting a minimum number of samples required to be at a leaf node (`min_samples_leaf`). Cross-validation can also help identify the best hyperparameters for your model.
What are some methods to handle imbalanced datasets?
Handling imbalanced datasets can involve a few strategies such as resampling techniques like SMOTE (Synthetic Minority Over-sampling Technique) or undersampling the majority class. Another effective method is to use the `class_weight` parameter available in many Sklearn classifiers, including `DecisionTreeClassifier`, which assigns higher weights to the minority class during training.
In conclusion, Sklearn’s Decision Tree algorithm, when wielded correctly, can be a potent tool in your data science arsenal. Through careful tuning of hyperparameters, strategic feature selection, and adept handling of imbalanced datasets, you can significantly boost the performance and reliability of your predictive models. With these insights and strategies at your disposal, you are well on your way to mastering the Sklearn Decision Tree and enhancing your data science skills.